Oracle Database 11g Настройка производительности.
2. Инструменты для диагностики производительности
СУБД Oracle включает в себя ряд диагностических инструментов для сбора и хранения данных о производительности. При помощи этих инструментов сервер Oracle собирает информацию о всех происходящих в базе данных операциях. Можно выделить 3 основных типа собираемых Oracle диагностических данных: накапливаемая или аккумулированная (cumulative) статистика, метрики и срезы статистики (sampled statistics).
- Накапливаемая статистика представляет собой суммарные данные о количестве и продолжительности событий, произошедших в базе данных с момента старта экземпляра. Некоторые из них, как например "buffer busy waits" являются критичными для настройки производительности экземпляра, другие, как например "index block splits", менее критичны. Количественные показатели, используемые в накапливаемой статистике не представляют особого интереса, поскольку они собираются на протяжении достаточно большого периода времени. При анализе накапливаемой статистики стоит обратить внимание на события, занявшие суммарно наибольшее количество времени. Для корреляции событий в Oracle Database используется "временная модель" (time model). Каждому типу событий, зафиксированному в БД присваивается процент от времени базы данных (DB time), затраченный на его суммарное время выполнения.
- Метрики представляют собой количество произошедших событий в единицу измерения. Единицей измерения может быть например время в секундах, или какое либо измерение например транзакция, сессия или какое либо другое событие. Метрики являются базовой основой для проактивного мониторинга производительности. Для метрик можно установить пороговые значения, при достижении которых будет генерироваться предупреждение. Например вы можете установить пороговое значение на количество операций чтения в секунду, заполнения области архивирования (archive log area) более чем на 95%, или на какое либо событие в базе данных, например возникновение ошибки "snapshot too old".
- Срезы статистики являются частью Active Session History - одного из компонентов Diagnostics Pack и позволяют просмотреть статистику, собранную ранее в различных разрезах. (При наличии Diagnostics and tuining pack статистика хранится даже после перезапуска экземпляра.)
- Временная модель
- Топ событий ожидания
- Динамические представления производительности
- Alert log
- файлы трассировки
- Вкладка "Performance" в Oracle Enterprise manager
- Отчеты Stats Pack (используется крайне редко)
- Diagnostics pack
- Tuning pack
Alert log представляет собой хронологический журнал информационных сообщений и событий, зафиксированных во время работы БД. Он может содержать важную для диагностики информацию о работе экземпляра БД и об ошибках, возникающих во время его работы.
Файлы трассировки генерируются в процессе работы фоновых, пользовательских и серверных процессов в случае возникновения сбоев. В некоторых случаях в них может содержаться важная информация, необходимая для диагностики проблем с производительностью, например предупреждения в файлах трассировки LGWR (Log Writer) о записях в журналы повтора, выполнявшихся более 500 миллисекунд. Чаще всего в файлы трассировки записывается информация о зафиксированных сбоях и детальная отладочная информация.
Statspack представляет собой набор процедур и функций для диагностики и поддерживается всеми версиями БД. Используется крайне редко, зачастую вместо него используется Diagnostic and tuining pack.
Преимущество Diagnostic and tuining pack в том что помимо автоматического создания срезов данных о производительности экземпляра, данные автоматически обрабатываются и выдаются базовые рекомендации по настройке. Statspack нужно запускать в ручную. Кроме того отчеты AWR, входящие в состав Diagnostic and tuining pack содержат более детальную информацию в более удобном для восприятия виде форматированного html отчета, что значительно упрощает процесс их анализа.
Основными целями настройки производительности являются:
- Сокращение времени отклика или времени ожидания пользователя
- Увеличение пропускной способности, что значит уменьшение времени на выполнение операции
- Сокращение времени восстановления экземпляра в случае сбоя
Цели настройки производительности могут быть сформулированы как "Выполнить больше за меньший отрезок времени". В некоторых случаях приходится искать баланс. Например в высоко нагруженных OLTP системах может быть допустимо увеличение времени ожидания пользователя для увеличения суммарного объема пользовательских операций. Цели настройки производительности должны ставиться в соответсвии со спецификой систем, работающих с БД. В хранилищах данных например может быть принято решение о сокращении производительности обработки данных в пользу сокращения времени восстановления в случае сбоя, поскольку продолжительное время восстановления влечет за собой большие финансовые потери клиента.

Топ 5 событий ожидания - блок отчета AWR, с которого лучше всего начать диагностику. В этом блоке всегда содержится информация, в данном случае события ожидания "buffer busy waits" и "free buffer waits" суммарно потребляют более, чем 56% времени базы данных. Эти два события дают направление для дальнейшего изучения. В данном случае они говорят о проблемах связанных с кешем буферов.
Время базы данных

Настройка производительности заключается не только в сокращении времени ожидания. Её целью является увеличение времени отклика до конечного пользователя и/или минимизация среднего количества ресурсов, используемых для обработки запроса. В одном случае целью настройки являются оба фактора, в другом приходится искать оптимальный баланс. (Например в случае параллельного выполнения запроса) Любой запрос к базе данных состоит из двух разных фаз: время ожидания (DB wait time) и время выполнения (DB CPU time). Время ожидания - это совокупность всех событий ожидания различных ресурсов БД. Время выполнения - это в свою очередь совокупность всех фаз выполнения, во время которых идет реальная обработка данных. Эти две фазы не обязательно составляют одну операцию выполнения и одно событие ожидания.Зачастую процесс некоторое время ожидает высвобождения ресурсов БД, затем на короткое время запускает обработку данных процессором, затем любой из перечисленных процессов повторяется. Процесс настройки производительности состоит в сокращении или исключении времени ожидания и в тоже время сокращении времени обработки. Данное утверждение верно для любого типа систем как OLTP, так и для Хранилищ данных. В высоко нагруженных системах показатели времени ожидания как правило завышены, так как фаза обработки данных требует больше ресурсов.


В процессе настройки производительности системы важно сопоставлять процессорное время с временем ожидания. Сравнивая эти два измерения можно понять какое количество времени затрачено на реальную обработку данных, и какое количество затрачено на ожидание системных ресурсов потенциально занятых другими процессами.
Временная модель
В процесс настройки производительности вовлечено множество компонентов СУБД Oracle и каждый из этих компонентов имеет собственную статистику. Как можно измерить потенциальный прирост производительности в целом ? Например, увеличится ли производительность системы если перенести часть памяти занятой из кэша буферов в разделяемый пул? При комплексном подходе к настройке производительности время †является единственным общим измерением для сравнения производительности компонентов БД. Большинство компонентов Oracle Database задействованных в настройке измеряют показатели производительности в единице времени. Данные временной модели хранятся в представлениях V$SYS_TIME_MODEL и V$SESS_TIME_MODEL. Временная модель содержит количественные показатели эффективности операций над базой данных. Наиболее важным показателем статистики, содержащейся во временной модели является DB time. Статистика содержащаяся во временной модели отражает общее время затраченное на обработку обращений пользователей к базе данных и общую нагрузку на экземпляр, что означает суммарное время процессорного времени и времени затраченного на события ожидания (для не простаивающих сессий).
Главной задачей настройки производительности базы данных Oracle является сокращение времени, которое пользователи затрачивают на выполнение каких либо действий в БД, другими словами на DB time.

Отношения между компонентами статистики временной модели представлены на рисунке выше. Статистика временной модели образует 2 дерева: время затраченное на исполнение фоновых процессов и время базы данных














Временная модель
В процесс настройки производительности вовлечено множество компонентов СУБД Oracle и каждый из этих компонентов имеет собственную статистику. Как можно измерить потенциальный прирост производительности в целом ? Например, увеличится ли производительность системы если перенести часть памяти занятой из кэша буферов в разделяемый пул? При комплексном подходе к настройке производительности время †является единственным общим измерением для сравнения производительности компонентов БД. Большинство компонентов Oracle Database задействованных в настройке измеряют показатели производительности в единице времени. Данные временной модели хранятся в представлениях V$SYS_TIME_MODEL и V$SESS_TIME_MODEL. Временная модель содержит количественные показатели эффективности операций над базой данных. Наиболее важным показателем статистики, содержащейся во временной модели является DB time. Статистика содержащаяся во временной модели отражает общее время затраченное на обработку обращений пользователей к базе данных и общую нагрузку на экземпляр, что означает суммарное время процессорного времени и времени затраченного на события ожидания (для не простаивающих сессий).
Главной задачей настройки производительности базы данных Oracle является сокращение времени, которое пользователи затрачивают на выполнение каких либо действий в БД, другими словами на DB time.

Отношения между компонентами статистики временной модели представлены на рисунке выше. Статистика временной модели образует 2 дерева: время затраченное на исполнение фоновых процессов и время базы данных
- Время базы данных: Количество времени в миллисекундах, затраченного базой данных на выполнение пользовательских запросов. DB time не включает в себя время, затраченное экземпляром на фоновые процессы например на PMON. DB time измеряется суммарно с момента запуска экземпляра. Поскольку DB time расчитывается из суммы не простаивающих пользовательских сессий, существует вероятность того, что значение DB time будет выше количества времени с момента старта экземпляра. Например экземпляр может быть запущен 30 минут назад может обрабатывать пользовательские запросы, суммарное время базы данных которых будет составлять 120 минут.
- DB CPU: Количество процессорного времени (в микросекундах) потраченного базой данных на выполнение пользовательских запросов. CPU time включает в себя процессы постановки в очередь.
- Время, затраченное на загрузку последовательностей (Sequence): Если последовательность закеширована, количество времени потраченного на пополнение кэша, после того как закончились закешированные значения. Когда номер последовательности выделяется из пула, время на его выделение не затрачивается. Для не закэшированных последовательностей время затрачивается при каждом вызове процедуры NEXTVAL
- Время, затраченное на разбор (Parse time): Количество времени, затраченное на операции разбора SQL. Включает в себя операции Hard и Soft разбора.
- Время, затраченное на Hard разбор: Количество времени, затраченное на операции Hard разбора SQL.
- Время, затраченное на выполнение SQL: Количество времени, затраченное на выполнение SQL выражений SELECT. Включено также время на выполнение захвата данных для результата.
- Время, затраченное на обработку пользовательских соединений: Количество времени, затраченное на обработку операций connect и disconnect для пользовательских сессий.
- Время, затраченное на обработку ошибок разбора (failed parse): Количество времени, затраченное на операции разбора, завершившихся в конечном счете ошибкой разбора.
- Время, затраченное на обработку ошибок разбора по причине отсутствия свободной разделяемой памяти (shared memory): Количество времени, затраченное на операции разбора, завершившихся в конечном счете ошибкой разбора из за отсутствия свободной разделяемой памяти.
- Время, затраченное на обработку ошибок разбора по причине отсутствия доступа к разделяемому курсору (sharing criteria): Количество времени, затраченное на операции жесткого разбора, завершившихся в конечном счете ошибкой разбора из за отсутствия доступа к существующему разделяемому курсору в кэше SQL.
- Время, затраченное на обработку ошибок разбора по причине несоответсвия связи (bind mismatch) : Количество времени, затраченное на операции жесткого разбора, завершившихся в конечном счете ошибкой разбора из за несоответствия типа или размера связи с существующим курсором в кше SQL.
- Время, затраченное на выполнение PL/SQL: Количество времени, затраченное на выполнение PL/SQL интерпретатора. Не включает в себя рекурсивное выполнение или операции разбора SQL выражений, а также время рекурсивно выполняющихся Java Virtual Machine выражений.
- Время, затраченное на вызов PL/SQL компилятора: Количество времени, затраченное на выполнение операций PL/SQL компилятора.
- Время, затраченное на выполнение вложенных PL/SQL RPC: Время, в течение которого выполняется вызов вложенных удаленных PL/SQL процедур. Включает в себя время рекурсивного выполнения SQL и Java, и поэтому не так просто может быть соотнесено со временем выполнения PL/SQL
- Время, затраченное на выполнение Java: Количество времени, затраченное на выполнение Java VM. Не включено время , затраченное на рекурсивное выполнение SQL и Java а также время на рекурсивное выполнение PL/SQL.
- Время на повторное установление связей. Время на повторное установление связей между значениями и Bind переменными.
- CPU time для фоновых процессов (в микросекундах): Количество времени, затраченное на выполнение фоновых запросов.
- Время выполнения фоновых запросов: Количество времени, суммарно потраченного на обработку фоновых запросов.
- RMAN CPU time (резервное копирование и восстановление): CPU time потраченное RMAN на операции резервного копирования и восстановления.
Пример показаний статистики временной модели

Приведенный выше пример взят из отчета AWR. Информация о
временной модели также доступна в отчетах Statspack. Статистика отсортирована
согласно % значения времени БД, таким образом область, потребляющая наибольшее
количество времени БД, и ее дочерние области находится в начале списка. В данном случае “sql execute elapsed
time” на ходится в начале списка. “Parse
time elapsed” и “hard parse elapsed time” являются дочерними операциями от “sql
execute elapsed time”. На данном примере наглядно видно, что операции жесткого
разбора заняли значительную часть от времени общего разбора и также время
разбора выражений заняло значительную часть от времени БД.
Сумма значений % времени БД в результате не даст 100% .
Процент времени БД для каждого компонента списка расчитывается индивидуально и
иногда включает смежные операции.
Динамические представления производительности

Сервер БД Oracle
управляет динамическим набором данных об операциях и производительности
экземпляра при помощи динамических представлений производительности. Данные представления основаны на виртуальных
таблицах, которые строятся из структур памяти внутри экземпляра. То есть, они
не являются обычными таблицами внутри БД. Представления V$ расширяют метаданные, хранящиеся в
структурах памяти экземпляра Oracle. представления V$ могут содержать данные ещё
до того как БД будет смонтирована или открыта. Представление V$FIXED_TABLE содержит список всех
динамических представлений.
Динамические представления содержат исходные данные, используемые AWR и Statspack для предоставления информации о:
- Сессиях
- Событиях ожидания
- Блокировках
- Статусе резервного копирования
- Использовании памяти
- Системных параметрах и параметрах сессии
- Статистике и метриках
Представления DICT и DICT_COLUMNS
также содержат имена динамических представлений производительности.
Пример использования динамических представлений производительности

Enterprise Manager использует динамические представления производительности, при необходимости, DBA также может выполнять запросы к динамическим представлениям производительности. Пример выше демонстрирует запросы, при помощи которых можно получить ответы на следующие вопросы:
- Какие SQL выражения и соответствующее им количество выполнения затрачивали при исполнении более чем 200 000 микросекунд?
- Какие сессии входили подключались к БД с машины EDRSR9P1 в течение последнего дня?
- ID сессий, которые в настоящее время блокируют других пользователей, и время блокировки. (block может иметь значение 1 или 0, показывая является ли сессия блокирующей)
Динамические представления производительности основываются на структурах памяти экземпляра, содержащие статистику, и позволяют просматривать множество статистики, которая в последующем используется для настройки производительности. Большенство содержащейся информации является показателями для специфических компонентов экземпляра.
Большенство динамических представлений производительности не используются администратором баз данных напрямую. Инструменты AWR и Statspack обедняют статистику и представляют её в более читабельном виде. Однако временами, очень полезно знать о существовании тех или иных представлений производительности для исследования деталей.
Некоторые динамические представления содержат данные которые не могут быть применены ко всем состояниям экземпляра БД. Например, если экземпляр только что был запущен, но БД еще не смонтирована, вы можете обратиться V$BGPROCESS для просмотра списка фоновых процессов, запущенных в данный момент для экземпляра БД. Если в это же время запросить информацию о статусе файлов данных из V$DATAFILE, мы получим ошибку ORA-01507 database not mounted поскольку в процессе монтированная БД происходит чтение контрольного файла для идентификации файлов данных.
Представления производительности основываются на структурах памяти и данные в них суммарные с момента запуска экземпляра. После перезапуска данные сбрасываются. По этому, вы не сможете узнать какое количество раз Х (например физическое чтение) происходило в промежутке времени с T1 до T2, вычислив дельту этого отрезка времени для экземпляра, если он был перезагружен в этом промежутке.
Поскольку все чтения данных представлений являются текущими, для динамических представлений производительности отсутствует механизм блокировки, то есть нет гарантии того, что данные из этих представлений будут прочитаны последовательно. Время от времени можно увидеть аномалии в статистике, когда одна или более таблица, относящаяся к соответствующей статистике была обновлена, однако не все таблицы завершили обновление когда выполнялась выборка.
Минимальная роль, которая требуется пользователю для того чтобы просматривать представления V$ - SELECT_CATALOG_ROLE. Хорошей практикой с точки зрения безопасности доступа к данным является создание отдельной роли, основанной на SELECT_CATALOG_ROLE, но с более узким списком объектов, доступных для нее.
Уровни статистики

Уровень статистики собираемой в базе данных определяется установкой значения для параметра STATISTICS_LEVEL для экземпляра БД. Значения данного параметра могут быть следующие:
- BASIC: Статистика для advisor-ов и другие статистические данные не собираются. Вы можете вручную выставить значения параметров, например таких как TIMED_STATISTICS и DB_CACHE_ADVICE. Множество статистики, необходимой для построения опорных линий (baseline) также не собирается. Oracle настоятельно рекомендует не использовать данное значение параметра STATISTICS_LEVEL, поскольку оно делает невозможным использование автоматического управления памятью экземпляра.
- TYPICAL: Значение по умолчанию. Данные собираются для статистики на уровне сегментов, временной модели и для всех adviser-ов. Значения других параметров для сбора статистики по отдельным компонентов перезаписываются при установке значения STATISTICS_LEVEL в TYPICAL.
- ALL: Сбор ведется для всех уровней TYPICAL статистики, дополнительно собирается временная статистика из операционной системы и статистика по обработке исходных данных из строк. Значения других параметров для сбора статистики по отдельным компонентов перезаписываются.
Для того чтобы просмотреть значения параметров статистики, установленные в данный момент для экземпляра, необходимо выполнить запрос к v$statistics_level вида:
select statistics_name, activation_level
from v$statistics_level
order by 2;
Пример результата выполнения:

Значения данных параметров для сбора статистики могут быть также установлены вручную. В данные параметры входят:
- TIMED_STATISTICS: Имеет значение TRUE если собирается статистика для временной модели.
- DB_CACHE ADVICE: Принимает следующие значения:
- OFF: Статистика отсутствует и память не используется.
- READY: Статистика еще не собрана, но память выделена. Установка значения параметра в READY перед установкой значения в ON предупреждает возможность возникновения ошибок сбора статистики, связанных с утилизацией памяти выделенной в буферном кэше.
- ON: Статистика собирается и память выделена. Изменение значения с OFF на ON может привести к ошибке, если требуемая память недоступна.
- TIMED_OS_STATISTICS: Определяет интервал (в секундах), в который экземпляр Oracle собирает статистику операционной системы, когда запрос выполняется от клиента к серверу или когда запрос завершается.
Когда параметр STATISTICS_LEVEL модифицируется командой ALTER SESSION, для текущей сессии включаются или отключаются следующие параметры сбора статистики:
- Timed statistics
- OS Statistics
- Plan Execution Statistics
Активность экземпляра и статистика событий ожидания

База данных Oracle управляет группой метрик, относящейся к внутренней активности экземпляра. Эти метрики представляются DBA в динамических представлениях производительности. Множество представлений отражают набор статистических показателей, которые начались с 0 после старта экземпляра и постоянно накапливаются вплоть до его остановки.
Активность экземпляра и статистика событий ожидания 2 ключевых класса метрик, используемых в процессе исследования причин падения производительности.
Статистика активности экземпляра предоставляется разработчиками для отладки различных функций программного обеспечения. Она может быть связана или не связана напрямую с событиями ожидания или другими метриками. Некоторые метрики данной группы, такие как например "parse time cpu", "physical reads", "user commits" могут быть использованы для диагностики производительности. Полный список показателей статистики активности экземпляра можно получить, обратившись к динамическому представлению V$STATNAME, аккумулированные значения этих показателей содержатся в представлении V$SYSSTAT.
События ожидания - это счетчики, которые увеличиваются серверным процессом или потоком для того чтобы показать что он ждет, когда требуемый ему ресурс станет доступен или произойдет другое требуемое событие перед тем как процесс или поток продолжит выполнение.
Статистика событий ожидания выявляет различные симптомы проблем, которые могут влиять на производительность, такие например как "latch contention"(конкуренция за защелку), "buffer contention" (конкуренция за кэш буферов), "I/O Contention". Необходимо помнить, что события ожидания являются симптомами проблемы, а не её действительной причиной. Полный список событий ожидания для экземпляра можно получить из динамического представления V$EVENT_NAME, статистику возникновения по каждому событию ожидания можно получить из представления V$SYSTEM_EVENT.
Метрики БД представляют сырые данные, которые используются для определения области, которую необходимо оптимизировать. Statspack и AWR делают снимки этих данных, выполняют вычисления, основанные на сделанных снимках, и предоставляют отчеты основанные на полученной информации. AWR в отличие от Statspack предоставляет рекомендации по настройке производительности используя Automatic Database Diagnostic Monitor (ADDM). AWR включает дополнительную информацию, которая не включена в отчет Statspack, а также формирует отчет в формате HTML.
Классификация системной статистики

На рисунке выше представлены классы статистики, содержащиеся в представлениях V$SESSTAT и V$SYSSTAT. Необходимость классификации статистики обусловлена огромным количеством показателей. Каждый показатель может относиться к одному или нескольким классам. Столбец CLASS для каждой статистки содержит число, представляющее один или несколько статистических классов. Ниже представлен пример статистических классов:
- 1, User
- 2, Enqueue
- 8, Cache
- 16, OS
- 32, Real Application Clusters
- 64, SQL
- 128, Debug
Например, значение класса 72 представляет статистику, относящуюся к SQL выражениям и кешированию. Некоторая статистика собирается и публикуется только при значении TRUE, установленном для параметра TIMED_STATISTICS.
Просмотр статистики
Сервер БД отражает сводную статистику активности экземпляра в динамическом представлении V$SYSSTAT. Для всех уровней можно присоединить идентификатор статистического показателя используя представление V$STATNAME.
Системная статистика

Все статистические представления содержат столбцы NAME, CLASS и VALUE. Представления уровня сервиса содержат дополнительно столбец SERVICE_NAME, представления уровня сессии содержат дополнительно столбец SID (идентификатор сессии). Это позволяет связать представления V$SESSION и V$SERVICE_NAME.
Статистика уровня сервиса содержит аккумулированные данные с момента запуска экземпляра. Имя сервиса позволяет собирать статистику по имени сервиса указанному в подключении. Это значительно упрощает мониторинг производительности отдельного приложения. Каждый пользователь при подключении использует специфическое имя сервиса к которому он подключается.
Пример:
В любом экземпляре всегда работает минимум 2 системных сервиса SYS$BACKGROUND и SYS$USERS. Дополнительно может быть создано до 116 различных сервисов на экземпляр. Сервисы регистрируются указанием параметра SERVICE_NAMES для экземпляра или пакетом DBMS_SERVICE. Данные сервиса кумулятивны с момента запуска экземпляра. Для получения кумулятивных данных сервиса используется динамическое представление V$SERVICE_STATS.

Статистика относящаяся к сессии
Просмотреть текущую информацию для каждого пользователя, в настоящий момент подключенного к БД можно используя динамическое представление V$SESSION. Сервер БД Oracle отображает суммарную статистику сессий в представлении v$SESSTAT и статистику для текущей сессии в представлении V$MYSTAT.
Пример:
Определить сессии которые потребляют более, чем 30 000 байт PGA.

Статистика SGA

Представление V$SGAINFO предоставляет информацию о текущем размере компонентов SGA, размере гранулы, и свободной памяти. Кратко данная информация представлена в V$SGA. Вся суммарная статистика памяти отражается в представлении v$SGASTAT. Можно обратится к данному представлению для получения аккумулированной статистики по использованию памяти, выделенной для SGA с момента старта экземпляра.
Пример:

События ожидания

Все события ожидания перечислены в представлении V$EVENT_NAME включая:
-
Free buffer waits
-
Latch free
-
Buffer busy waits
-
Db file sequential read
-
Db file scattered read
-
Db file parallel write
-
Undo segment tx slot
-
Undo segment extension
Каждое событие привязано к определенному классу. Привязка также содержится в представлении V$EVENT_NAME. Каждое событие имеет дополнительные параметры, возвращаемые вместе с событием. Данные параметры и их значения представлены в столбцах PARAMETER1 и PARAMETER3.

Событие ожидания может иметь до трех дополнительных параметров. Это подразумевает, что значения этих параметров хранятся в столбцах PARAMETERn.
Событие ожидания Buffer busy waits
Событие ожидания "buffer busy waits" фиксирует события, которые требуют свободный буфер в буферном кеше. Возникновение данного события ожидания говорит о том, что несколько процессов одновременно пытаются получить доступ к одним и тем же буферам в буферном кеше.
С данным событием ожидания предоставляется 3 дополнительных параметра:
Событие ожидания Log File Switch (Checkpoint Incomplete)
Событие ожидания “log file switch (checkpoint incomplete)” регистрируется при возникновении ожидания переключения журнала, поскольку сессия не может записать изменения в текущий лог в REDO лог группе. Запись не может быть выполнена, поскольку checkpoint для этого лога не завершен. Для данного события ожидания не передается никаких параметров.


Статистика событий ожиданий сервиса
Представление V$SERVICE_EVENT показывает общее количество ожиданий для соответствующего события с момента старта экземпляра в разрезе сервисов. Представление v$SERVICE_WAIT_CLASS объединяет ожидания по сервису и классу ожидания.
 Статистика событий ожидания сессии
Статистика событий ожидания сессии
Представление V$SESSION_EVENT оказывает общее количество ожиданий для соответствующего события с момента старта экземпляра в разрезе сессий. Представление V$SESSION_WAIT содержит список ресурсов или событий которые ждут активные сессии. V$SESSION также включает информацию о том чего в настоящий момент ждет сессия.
В процессе диагностики необходимо знать какой из процессов ждет освобождения каких либо ресурсов. Структура представления V$SESSION_WAIT делает проще определение в реальном времени того, какие из процессов чего ждут и почему.


• SEQ#: номер последовательности, идентфтцирующий ожидание
• EVENT: Ресурс или событие которого ожидает сессия
• STATE: Текущее состояние ожидания. Возможные значения:
• WAITING – сессия в данный момент ждет
• WAITED UNKNOWN TIME – Продолжительность последнего ожидания не известна, это значение устанавливается когда параметр TIMED_STATISTICS установлен в значение false
• WAITED SHORT TIME - Последнее ожидание заняло менее микросекунды • WAITED KNOWN TIME - Продолжительности последнего ожидания отображается в колонке WAIT_TIME_MACRO
Каждый из трех параметров (P1, P2, P3) имеет следующие столбцы
• P1TEXT: Описание первого дополнительного параметра, который относистся к PARAMETER1 описаному в представлении V$EVENT_NAME
• P1: Значение первого дополнительного параметра
• P1RAW: Значение первого дополнительного параметра, в шестнадцатиричном представлении
• WAIT_TIME
Описание значений
> 0 последнее время ожидания сессии
= 0 сессия в данный момент ожидает чего либо
= –1 значеение меньше чем 1/100 секунды
= –2 система не может передать временной параметр
• SECONDS_IN_WAIT: Количество времени ожидания в секундах
• STATE: Waiting, Waited Unknown Time, Waited Short Time (менее ожной тысячной секунды), или Waited Known Time (значение хранится в колонке WAIT_TIME)


Событие ожидания Buffer busy waits
Событие ожидания "buffer busy waits" фиксирует события, которые требуют свободный буфер в буферном кеше. Возникновение данного события ожидания говорит о том, что несколько процессов одновременно пытаются получить доступ к одним и тем же буферам в буферном кеше.
С данным событием ожидания предоставляется 3 дополнительных параметра:
- FILE# и BLOCK#: Данные параметры идентифицируют номер блока в файле данных, который идентифицируется номером файла, для каждого блока доступ к которому приводит к ожиданию.
- ID: Событие ожидания "buffйr busy waits" вызывается из разных мест пользовательской сессии. Каждое из этих мест помещает ссылку в ядро по разным причинам. ID определяет место в сессии из которого вызвано событие ожидания.
Событие ожидания Log File Switch (Checkpoint Incomplete)
Событие ожидания “log file switch (checkpoint incomplete)” регистрируется при возникновении ожидания переключения журнала, поскольку сессия не может записать изменения в текущий лог в REDO лог группе. Запись не может быть выполнена, поскольку checkpoint для этого лога не завершен. Для данного события ожидания не передается никаких параметров.
Классы Ожидания

Множество возможных событий ожидания, возможных в БД Oracle 11g категоризированы по классам ожидания основываясь на решении, предоставляемом этим событием. Каждое событие ожидания относится к одному классу. Это позволяет на высоком уровне анализировать события ожидания. Например exclusive transaction locks (TX) в целом проблема уровня приложения или например segment space management locks (HW) указывает на проблемы в конфигурации. Ниже представлены наиболее часто встречающиеся классы событий ожидания:
- Application: Ожидание блокировок вызванное блокировками на уровне срок или явной коммандной блокировкой.
- Administration: Команды DBA, которые являются причиной ожидания, например перестройка индекса.
- Commit: Ожидание подтверждения записи REDO log после commit.
- Concurrency: Конкурентный разбор и ожидание защелок и блокировок в буферном кеше.
- Configuration: Недостаточный размер лог буфера, лог файлов, буферного кеша, разделяемого пула, слота транзакции (ITL), HW enqueue contention или space allocation (ST) enqueue contention.
- User I/O: Ожидание за чтение блоков с диска
- Network Communications: Ожидание передачи данных по сети.
- Idle: События ожидания, относящиеся к неактивным сессиям, например событие ожидания "SQL*Net message from client"
Отображение статистики по событиям ожидания

Все события ожидания собраны в представлении V$EVENT_NAME.
Кумулятивная статистика событий ожидания для всех сессий хранится в представлении V$SYSTEM_EVENT, которое показывает общее количество ожиданий для соответствующего события с момента старта экземпляра. V$SERVICE_EVENT показывает кумулятивную статистику событий ожидания для каждого сервиса. V$SESSION_EVENT показывает кумулятивную статистику по событиям ожидания для каждой сессии.
Представление V$SERVICE_EVENT показывает общее количество ожиданий для соответствующего события с момента старта экземпляра в разрезе сервисов. Представление v$SERVICE_WAIT_CLASS объединяет ожидания по сервису и классу ожидания.

Представление V$SESSION_EVENT оказывает общее количество ожиданий для соответствующего события с момента старта экземпляра в разрезе сессий. Представление V$SESSION_WAIT содержит список ресурсов или событий которые ждут активные сессии. V$SESSION также включает информацию о том чего в настоящий момент ждет сессия.
В процессе диагностики необходимо знать какой из процессов ждет освобождения каких либо ресурсов. Структура представления V$SESSION_WAIT делает проще определение в реальном времени того, какие из процессов чего ждут и почему.

При дальнейшем исследовании необходимо выяснить какие из ожиданий возникают чаще других и по каким общим признакам они могут быть объединены, например они могут использовать одни программные модули. На примере представленном выше большенство возникших событий ожидания относятся к классу простаивающих ресурсов (Idle). Это не является проблемой в производительности.
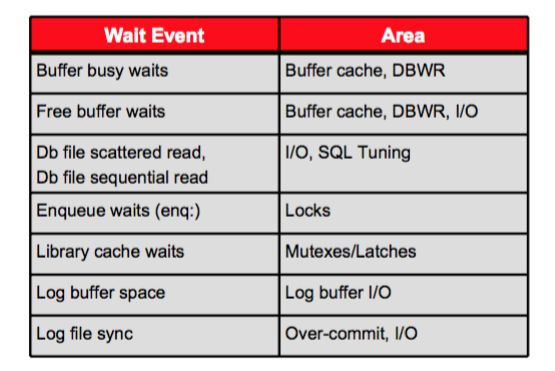
Наиболее часто встречающиеся события ожидания
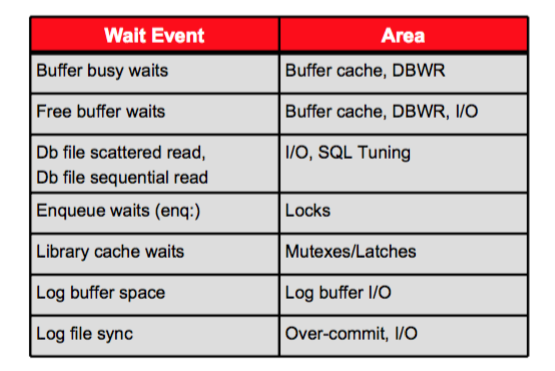
Использование представления V$SESSION_WAIT

Данное представление показывает список ресурсов или событий которых в настоящее время ожидает сессия. Эта информация также доступна в представлении V$SESSION. Данное представление полезно в диагностировании сессий, обрабатывающих запросы слишком медленно или зависших.
Параметр инициализации TIMED_STATISTICS
Для того чтобы поместить значения в колонку WAIT_TIME, необходимо установить значение TRUE параметра TIMED_STATISTICS. Этот параметр меняется динамически.
Колонки:
• SID: Идентификатор сессии• SEQ#: номер последовательности, идентфтцирующий ожидание
• EVENT: Ресурс или событие которого ожидает сессия
• STATE: Текущее состояние ожидания. Возможные значения:
• WAITING – сессия в данный момент ждет
• WAITED UNKNOWN TIME – Продолжительность последнего ожидания не известна, это значение устанавливается когда параметр TIMED_STATISTICS установлен в значение false
• WAITED SHORT TIME - Последнее ожидание заняло менее микросекунды • WAITED KNOWN TIME - Продолжительности последнего ожидания отображается в колонке WAIT_TIME_MACRO
Каждый из трех параметров (P1, P2, P3) имеет следующие столбцы
• P1TEXT: Описание первого дополнительного параметра, который относистся к PARAMETER1 описаному в представлении V$EVENT_NAME
• P1: Значение первого дополнительного параметра
• P1RAW: Значение первого дополнительного параметра, в шестнадцатиричном представлении
• WAIT_TIME
Описание значений
> 0 последнее время ожидания сессии
= 0 сессия в данный момент ожидает чего либо
= –1 значеение меньше чем 1/100 секунды
= –2 система не может передать временной параметр
• SECONDS_IN_WAIT: Количество времени ожидания в секундах
• STATE: Waiting, Waited Unknown Time, Waited Short Time (менее ожной тысячной секунды), или Waited Known Time (значение хранится в колонке WAIT_TIME)
Измерения системной статистики
Системная статистика измеряется в микро и милисекундах в зависимости от представления. Информация по измерениям представлена на рисунке ниже:

Использование преимуществ пакетов

Management пакеты показаны в левой стороне слайда. Все они требуют отдельной лицензии, которая может быть приобретена только с Enterprise версией БД. Функции пакетов доступны из Enterprise manager Database Control, Grid Control и API, предоставляемой вместе с программным обеспечением Oracle.
- Oracle Database Diagnostic pack предоставляет функциональность автоматической диагностики производительности и расширенного мониторинга. Ниже представлены составные компоненты этого пакета:
- пакет DBMS_WORKLOAD_REPOSITORY
- пакет DBMS_ADDM
- пакет DBMS_ADVISOR, если указать ADDM в качестве значения параметра ADVISOR_NAME или если указано значение параметра TASK_NAME начинающееся с ADDM.
- динамическое представление производительности V$ACTIVE_SESSION_HISTORY
- все представления словаря данных начинающиеся с префикса DBA_HIST_ вместе со связанными таблицами.
- все представления словаря данных начинающиеся с префикса DBA_ADVISOR_ если запрос к этим представлениям возвращает значение ADDM в столбце ADVISOR_NAME или значение ADDM* в столбце TASK_NAME соответствующее TASK_ID.
- представление DBA_STREAMS_TP_PATH_BOTTLENECK
- все представления начинающиеся с DBA_ADDM_
- следующие отчеты из директории /rdbms/admin: awrrpt.sql, awrrpti.sql, addmrtp.sql, addmrpti.sql, ashrpt.sql, ashrpti.sql, awrddrpt.sql, awrddrpi.sql, awrsqrpi.sql, awrsqrpt.sql, awrextr.sql, and awrload.sql, awrextr.sql, awrload.sql, awrinfo.sql, spawrrac.sql.
- Oracle tuning pack представляет экспертные инструменты для настройки производительности окружения Oracle, включающие в себя настройку SQL и оптимизацию хранения данных. Следовательно, для использования Tuning pack вы также должны иметь Diagnostic pack. Ниже представлены составные компоненты этого пакета:
- пакет DBMS_SQLTUNE
- пакет DBMS_ADVISOR когда значение параметра ADVISOR_NAME SQL Tuning Advisor или SQL Access Advisor.
- V$SQL_MONITOR
- V$SQL_PLAN_MONITOR
- скрипт sqltrpt.sql расположенный в директории /rdbms/admin.
- Oracle Configuration Management pack автоматизирует потребляющие время и исключает ошибки в процессе конфигурации ПО, отслеживания изменений в окружении, установке патчей, клонировании и управлении политиками.
- Oracle Provisioning pack автоматизирует процесс установки программного обеспечения, приложений и патчей для базы данных и операционной системы на которую она установлена.
Для того чтобы активировать дополнительные пакеты необходимо установить значение DIAGNOSTIC+TUNING для параметра CONTROL_MANAGEMENT_PACK_ACCESS
Использование информации из alert.log в процессе настройки производительности
Alert.log содержит следующие данные, которые могут быть использованы для диагностики производительности экземпляра:
- Время выполнения архивирования
- Время начала и завершения процесса восстановления экземпляра
- Deadlock и Timeout ошибки
- незавершенные операции checkpoint
- Время начала и окончания операции checkpoint
Alert.log может расти до неуправляемых размеров. Его можно удалять без последствий даже при запущенном экземпляре БД, несмотря на это рекомендуется сделать его архивную копию перед удалением. Она может пригодиться, если в будущем потребуется разбираться с проблемой, возникшей ранее.
Файлы трассировки пользователей
Серверный процесс может генерировать файлы трассировки по запросу пользователя или администратора БД.
Трассировка на уровне экземпляра
Трассировка на уровне экземпляра должна применяться в случае крайней необходимости. Трассировка всех сессий создаст повышенную нагрузку на системы ввода/вывода и быстро может переполнить дисковое пространство. Данный вид трассировки включается и выключается функцией DBMS_MONITOR.DATABASE_TRACE_ENABLE().
Трассировка на уровне сессии
Трассировка на уровне сессии включается командой: EXECUTE DBMS_MONITOR.SESSION_TRACE_ENABLE(8,12, waits => true, binds => true)
, где 8 и 12 системный идентификатор и серийный номер сессии. В большинстве случаев только DBA имеет доступ к включению трассировки в БД.
Пакет DBMS_MONITOR создается во время запуска скрипта catproc.sql. Этот скрипт расположен в директории $ORACLE_HOME/rdbms/admin/
Для того чтобы включить трассировку текущей сессии необходимо выполнить команду: EXECUTE DBMS_SESSION.SET_SQL_TRACE(TRUE)
Трассировка фоновых процессов
Сервер БД Oracle сбрасывает информацию об ошибках, зафиксированных фоновым процессом в файлы трассировки. Oracle Support использует эти файлы трассировки для диагностики и устранения проблем. Эти файлы обычно не содержат полезной для настройки производительности информации. В то же время используя систему events DBA может направить информацию, требуемую для настройки производительности в файл трассировки фонового процесса. Исключением для данного правила является event 10053 который не модет быть использован для трассировки вариантов выбора схемы стоимостного оптимизатора.
Файлы трассировки пользователей
Серверный процесс может генерировать файлы трассировки по запросу пользователя или администратора БД.
Трассировка на уровне экземпляра
Трассировка на уровне экземпляра должна применяться в случае крайней необходимости. Трассировка всех сессий создаст повышенную нагрузку на системы ввода/вывода и быстро может переполнить дисковое пространство. Данный вид трассировки включается и выключается функцией DBMS_MONITOR.DATABASE_TRACE_ENABLE().
Трассировка на уровне сессии
Трассировка на уровне сессии включается командой: EXECUTE DBMS_MONITOR.SESSION_TRACE_ENABLE(8,12, waits => true, binds => true)
, где 8 и 12 системный идентификатор и серийный номер сессии. В большинстве случаев только DBA имеет доступ к включению трассировки в БД.
Пакет DBMS_MONITOR создается во время запуска скрипта catproc.sql. Этот скрипт расположен в директории $ORACLE_HOME/rdbms/admin/
Для того чтобы включить трассировку текущей сессии необходимо выполнить команду: EXECUTE DBMS_SESSION.SET_SQL_TRACE(TRUE)
Трассировка фоновых процессов
Сервер БД Oracle сбрасывает информацию об ошибках, зафиксированных фоновым процессом в файлы трассировки. Oracle Support использует эти файлы трассировки для диагностики и устранения проблем. Эти файлы обычно не содержат полезной для настройки производительности информации. В то же время используя систему events DBA может направить информацию, требуемую для настройки производительности в файл трассировки фонового процесса. Исключением для данного правила является event 10053 который не модет быть использован для трассировки вариантов выбора схемы стоимостного оптимизатора.
Комментариев нет:
Отправить комментарий