Oracle Database 11g Настройка производительности.
Стоимостной оптимизатор (Cost based optimizer)
Структурированный язык запросов (SQL)

Все программы для доступа к пользовательским данным в Oracle Database напрямую или нет так или иначе в итоге используют SQL. SQL можно разделить на шесть основных категорий:
- Data manipulation language (DML) - манипуляции с данными существующих объектов и схем.
- Data definition language (DDL) - создание, изменение структуры или удаление объектов схем.
- Transaction control statements (TCS) - управление изменениями, вносимыми DML и группировка DML выражений в транзакции.
- System Control statements - изменение параметров экземпляра.
- Session Control statements - изменение параметров сессии.
- Embedded SQL statements - вложенный DDL, DML и TCS, выполняемый в рамках программы процедурного языка, такого как PL/SQL и прекомпилятор Oracle. Это включение осуществляется с помощью выражений указанных в категории ESS на рисунке выше.
Представление SQL выражения
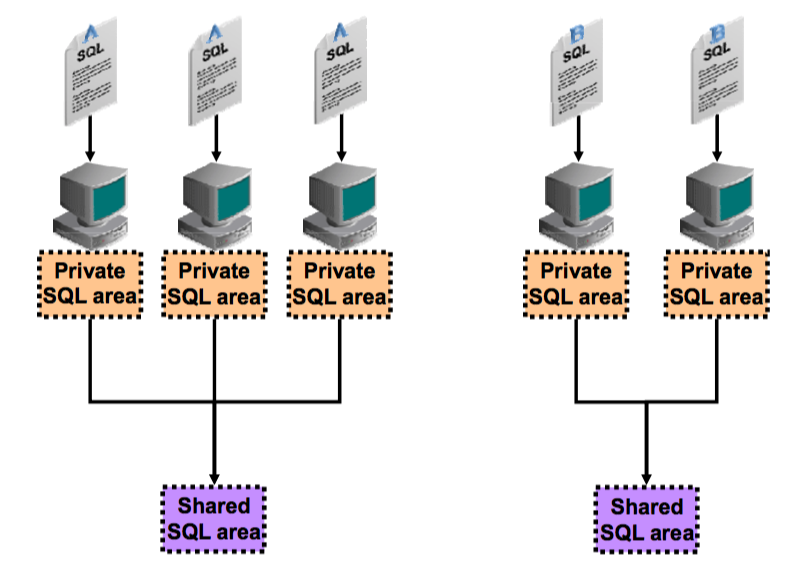
База данных Oracle представляет каждое из выражений SQL в таком виде, чтобы оно могло использовать общедоступные ресурсы в процессе его обработки. П процессе обработки SQL используются как частные так и общие области памяти. Экземпляр Oracle автоматически определяет когда SQL выполняется повторно или одновременно несколькими пользователями и использует для его выполнения общие области памяти. В тоже время каждый пользователь может иметь собственную копию выражения в частной области SQL.
Общая область SQL содержит информацию об оптимизации, необходимую для выполнения выражения, в то время как частная область SQL содержит всю информацию, касающуюся текущего выполнения SQL выражения.
Реализация обработки SQL выражений

База данных Oracle создает и использует структуры памяти для разных нужд. Например в памяти хранится программный код который сейчас работает, данные к которым есть общий доступ пользователей, и частные пользовательские области для каждого подключенного пользователя.
База данных Oracle выделяет память из разделяемого пула когда разбирается новое SQL выражение, для того чтобы хранить результат разбора. Объемы выделяемой памяти зависят от комплексности SQL выражения. Если для выполняемого выражения уже была выделена память в разделяемом пуле со временем помещенные в разделяемый пул выражения вытесняются по сценарию LRU после окончания свободного пространства в разделяемом буфере. Если SQL выражение было вытеснено из разделяемого пула, при его следующем выполнении оно должно быть заново разобрано и помещено в разделяемый пул.
Для чего нужен оптимизатор?

Оптимизатор должен всегда возвращать корректный результат настолько быстро, насколько это возможно. Оптимизатор стоимости пытается определить какой план исполнения наиболее эффективен сравнив доступные пути доступа к данным и данные факторинга, основанного на статистике объектов схемы к которым обращается SQL выражение.




- Оптимизатор генерирует набор потенциальных планов выполнения основываясь на данных указанных выше.
- Оптимизатор определяет стоимость каждого из планов основываясь на статистике из словаря данных для определения распределения данных а также на характеристики доступа к данным при помощи таблиц и индексов.
- Оптимизатор сравнивает стоимость планов и выбирает план с наиболее низкой стоимостью.
Оптимизация в процессе выполнения жесткого разбора

Оптимизатор создает план выполнения для SQL выражения.
SQL запросы, выполняющиеся в системе сначала проходят фазу разбора, в процессе которой проверяется синтаксис и анализируется семантика выражения. Результатом выполнения этой фазы является разобранное представление выражения состоящее из нескольких блоков запроса. Блок запроса - это самостоятельное по отношению к таблице DML выражение. Блок запроса может быть DML верхнего уровня или подзапросом. Представление выражения после разбора передается оптимизатору, который отвечает за три основные функции: трансформацию, вычисление стоимости и генерацию плана выполнения.
Перед подсчетом стоимости система может трансформировать выражение в эквивалентное ему и посчитать стоимость для эквивалентного выражения.
Входящими данными для трансформатора запросов служит разобранный запрос, представленный в виде набора взаимосвязанных блоков запроса. Основная задача оптимизатора стоимости заключается в определении возможных преимуществ, полученных в результате изменения структуры запроса для генерации оптимального плана выполнения. Некоторые техники трансформации запросов применяются трансформатором запросов, такие как например транзитивность, слияние представлений, изменение предиката, вывод подзапроса в отдельный блок, изменение кода запроса (query rewrite), трансформация типа "звезда" и замена конструкции OR.
Пример замены конструкции OR при трансформации запроса:

Если запрос содержит в блоке WHERE множественные условия объединенные оператором OR, оптимизатор трансформирует его в эквивалентный запрос с использованием объединения данных при помощи конструкции UNION ALL, это позволяет выполнять запрос более эффективно.
Например если на каждый столбец в условии создан отдельный индекс, оптимизатор может перестроить запрос таким образом, чтобы он сканировал каждый индекс в отдельности, а потом объединял данные вместе.
На примере выше переписанный запрос будет использовать индексы на столбцы JOB и DEPTNO для получения доступа к данным вместо полного сканирования таблиц, как было бы в случае выполнения оригинального SQL выражения.
Пример вывода под-запроса в основной запрос:

Чтобы вывести под-запрос в главный запрос оптимизатор может принять решение использовать конструкцию JOIN как показано на рисунке выше. Оптимизатор не может преобразовать под-запросы со сложными составными условиями.
Пример слияния представления:

Для слияния запроса, лежащего в основе представления с связанным блоком запроса оптимизатор заменяет имя представления именами его базовых таблиц в блоке запроса и добавляет условие, содержащееся в блоке WHERE представления в блок WHERE основного запроса.
Этот тип оптимизации применим для представлений типа select-project-join, которые содержат только выборку, прогнозы и соединения. Сливаемое представление не должно содержать set операторы, агрегированные функции DISTINCT, GROUP BY, CONNECT BY и т. д.
Трансформация запроса пример добавления предиката:

Оптимизатор может трансформировать блок запроса который получает доступ к не объединенному представлению, вставив предикат содержащийся в блоке запроса в текст запроса представления.
На примере на слайде представление two_emp_tables является объединением двух таблиц с сотрудниками. Представление определено двумя запросами объединенными между собой оператором UNION.
Поскольку представление содержит в себе объединение двух запросов, оптимизатор не может выполнить операцию слияния представления и исходного кода выражения в блок запроса. Однако оптимизатор может трансформировать выражение, добавив предикат, условие WHERE deptno = 20 в исходный код представления. Трансформированный запрос указан в нижней части рисунка. Если создан индекс для колонки DEPNO в обеих таблицах, он будет использован.
Пример транзитивности:



При выполнении операции соединения, важно знать кардинальность строк участвующих в соединении в ведущей таблице. Например в случае использования вложенных циклов в процессе соединения таблиц набор строк из ведущей таблицы определяет, как часто система должна просканировать ведомую таблицу.
Поскольку стоимость операций сортировки напрямую зависит от количества и размера строк, которые будут сортироваться, показатель кардинальности также имеет важное значение для нее.
В примере приведенном выше, основываясь на предполагаемой статистике, оптимизатор знает что в столбце DEV_NAME имеется 203 уникальных значения, и что общее число строк в таблице courses составляет 1018. Основываясь на этом предположении, оптимизатор делает вывод о том, что селективность предиката DEV_NAME='ANGEL' равняется 1/203 (предполагается что для данных нет гистограмм) и предполагаемая кардинальность запроса будет равна (1/203)*1018. Затем это значение округляется до большего целого, в данном случае до 6.


Этот тип оптимизации применим для представлений типа select-project-join, которые содержат только выборку, прогнозы и соединения. Сливаемое представление не должно содержать set операторы, агрегированные функции DISTINCT, GROUP BY, CONNECT BY и т. д.
Трансформация запроса пример добавления предиката:

Оптимизатор может трансформировать блок запроса который получает доступ к не объединенному представлению, вставив предикат содержащийся в блоке запроса в текст запроса представления.
На примере на слайде представление two_emp_tables является объединением двух таблиц с сотрудниками. Представление определено двумя запросами объединенными между собой оператором UNION.
Поскольку представление содержит в себе объединение двух запросов, оптимизатор не может выполнить операцию слияния представления и исходного кода выражения в блок запроса. Однако оптимизатор может трансформировать выражение, добавив предикат, условие WHERE deptno = 20 в исходный код представления. Трансформированный запрос указан в нижней части рисунка. Если создан индекс для колонки DEPNO в обеих таблицах, он будет использован.
Пример транзитивности:

Если два условия предиката связаны с общим столбцом, оптимизатор в определенных случаях может добавить дополнительное условие, используя принцип транзитивности. После этого оптимизатор может использовать добавленное в предикат условие для оптимизации доступа к данным. Данный тип трансформации позволяет оптимизатору использовать например дополнительный индекс созданный для поля, добавленного в условие.
Оптимизатор добавляет условие только для тех столбцов, для которых выполняются условия ссылочной целостности.
Стоимостной оптимизатор
Комбинация процессов вычислителя и трансформатора запроса называется стоимостным оптимизатором. (CBO)
Вычислитель генерирует три типа измерений для данных: селективность, кардинальность и стоимость. Все эти измерения связаны между собой. Кардинальность получается из селективности и также стоимость считается на основе кардинальности. Конечной целью вычислителя является определение общей стоимости заданного плана исполнения. Если доступна статистика, вычислитель использует её для повышения точности вычислений в процессе подсчета измерений.
Основной функцией генератора плана является сгенерировать максимальное количество вариантов плана выполнения запроса, и выбрать план с наиболее низкой стоимостью. Максимальное число планов выполнения запроса прямо пропорционально количеству операций соединения в блоке FROM. Число планов экспоненциально растет с ростом количества соединений.
Оптимизатор использует различные части информации для определения лучшего пути: блок WHERE, статистику, параметры инициализации, примененные подсказки оптимизатору (HINT), и информацию о схеме.
Определение селективности запроса

Селективность представляет доля строк из общего набора строк. Набором строк может быть таблица, представление или результат выполнения операции объединения или группировки. Селективность привязана к предикату запроса, например last_name='Smith' или к комбинации предикатов, например last_name='Smith' и job_type='Clerk'. Предикат играет роль фильтра, который отсеивает некоторое количество строк в наборе строк. Следовательно селективность предиката означает процент трок из набора строк, соответствующих условию. Селективность измеряется в диапазоне значений от 0.0 до 1.0. Значение 0.0 означает, что из набора строк не выбрано ни одной строки, 1.0 соответственно означает что выбраны все строки.
Если для набора данных нет статистики, оптимизатор использует динамический семплинг для определения селективности данных, размер семпла устанавливается параметром OPTIMIZER_DYNAMIC_SAMPLING. Когда статистика доступна, вычислитель использует её для вычисления селективности. Например для условия равенства в предикате (last_name='Smith') селективность устанавливается в значение, обратное количеству n уникальных значений LAST_NAME, поскольку запрос выбирает строки, которые содержат одно из n различных значений. В гистограмму помещается информация о распределении различных значений в столбце, что позволяет более точно вычистить селективность значений.
Определение кардинальности запроса

Простой пример вычисления кардинальности запроса:
SELECT days FROM courses WHERE dev_name = 'ANGEL'
- Количество уникальных строк в DEV_NAME - 203;
- Общее количество строк в таблице courses - 1018;
- Селективность = 1/203 = 4.926*e-03
- Кардинальность = (1/203)*1018 = 5.01 (округляется до 6)
При выполнении операции соединения, важно знать кардинальность строк участвующих в соединении в ведущей таблице. Например в случае использования вложенных циклов в процессе соединения таблиц набор строк из ведущей таблицы определяет, как часто система должна просканировать ведомую таблицу.
Поскольку стоимость операций сортировки напрямую зависит от количества и размера строк, которые будут сортироваться, показатель кардинальности также имеет важное значение для нее.
В примере приведенном выше, основываясь на предполагаемой статистике, оптимизатор знает что в столбце DEV_NAME имеется 203 уникальных значения, и что общее число строк в таблице courses составляет 1018. Основываясь на этом предположении, оптимизатор делает вывод о том, что селективность предиката DEV_NAME='ANGEL' равняется 1/203 (предполагается что для данных нет гистограмм) и предполагаемая кардинальность запроса будет равна (1/203)*1018. Затем это значение округляется до большего целого, в данном случае до 6.
Стоимость выполнения запроса:

Стоимость выражения представляет собой количество операций ввода/вывода требуемых для выполнения выражения вычисленное оптимизатором. Проще говоря, стоимость - это усредненное значение в разрезе количества беспорядочных чтений блоков.
Формула, указанная на рисунке выше состоит из трех основных измерений:
- Предположительное время, требуемое для выполнения всех операций беспорядочного одноблочного чтения
- Предположительное время выполнения многоблочного чтения
- Предположительное время CPU которое будет затрачено на обработку выражения

Генератор планов исследует множество планов выполнения запроса для блока запроса используя разные пути доступа к данным, методы и порядок объединения. В конечном счете генератор планов передает на исполнение вашего выражения лучший план. НА рисунке представлен файл трассировки оптимизатора для выполняемого запроса. Как видно на рисунке генератор планов построил 6 возможных планов выполнения запроса: два порядка соединения, и для каждого из них три разных типа соединения. Предполагается, что для таблиц, к которым обращается выражение нет индексов.
В примере выше соединяются две таблицы: DEPARTMENTS и EMPLOYEES. Для данного выражения может быть использовано 3 возможных метода соединения: Nested Loop, Sort Merge или HASH JOIN. Для каждого из планов указана стоимость. В данном случае оптимальным является план с методом соединения № 1.
Генератор планов использует внутренний механизм, который позволяет отбросить планы с более высокой стоимостью для сокращения времени обработки выражения. Если текущий оптимальный план имеет высокую стоимость, генератор планов более детально исследует планы исполнения и пытается сгенерировать более оптимальный план. Как только достигнута оптимальная стоимость выполнения для запроса, генератор планов останавливает поиск планов исполнения.
Контроль поведения оптимизатора
Поведение оптимизатора можно контролировать используя следующие параметры инициализации:
CURSOR_SHARING: определяет каким образом SQL выражение может разделить (повторно использовать) существующие курсоры:
- FORCE: Заставляет разделять курсор выражения, которые могут отличаться в нескольких символах без изменения смысла выражения.
- SIMILAR: Заставляет разделять курсор выражения, которые могут отличаться в нескольких символах без изменения смысла выражения или степени оптимизации плана выполнения выражения. Может влиять на производительность в DSS системах которые используют опорные линии для оптимизации планов выполнения.
- EXACT: Разделяют курсоры только полностью идентичные выражения. Значение по умолчанию.
DB_FILE_MULTIBLOCK_READ_COUNT - один из параметров, который можно использовать для минимизации ввода/вывода в процессе сканирования таблиц или быстрого сканирования индексов (index fast full scan). Он определяет максимальное число блоков, считываемых за одну операцию ввода / вывода при последовательном сканировании. Общее число операций ввода/вывода, необходимое для сканирования объекта зависит от таких факторов, как размер сегмента и использование параллельного выполнения для операции обработки. Значением по умолчанию этого параметра является значение, которое соответствует максимальному размеру ввода / вывода, который может быть выполнен эффективно. Это значение зависит от платформы и рассчитывается при запуске экземпляра для большинства платформ.
Поскольку параметр измеряется в блоках, он автоматически вычисляет значение, равное максимальному размеру ввода / вывода, который может быть выполнен эффективно, деленному на стандартный размер блока. Обратите внимание, что если число сессий очень велико,значение счетчика мультиблочного чтения уменьшается, чтобы избежать переполнения кэша буферов. Несмотря на то что значение по умолчанию может быть большим, оптимизатор не выбирает большие планы, если не установить этот параметр. Он будет делать это, только если явно установить этот параметр в большое значение. В принципе, если этот параметр не задан явно (или установлен 0), оптимизатор использует значение по умолчанию 8 при определении затрат на полные сканирования таблиц и индексов быстрого полного сканирования. Системы обработки транзакций (OLTP) и пакетные среды, как правило, имеют значения в диапазоне от 4 до 16 для этого параметра. DSS и среды хранения данных, как правило, получают наибольшую выгоду от максимизации значения этого параметра. Оптимизатор более вероятно, выберет полное сканирование таблицы вместо использования индекса, если значение этого параметра высокое.
PGA_AGGREGATE_TARGET - указывает количество памяти, выделяемое для PGA и доступное для всех серверных процессов подключенных к экземпляру. Установка параметра PGA_AGGREGATE_TARGET в не нулевое значение вызывает автоматическую установку параметра WORKAREA_SIZE_POLICY в значение AUTO. Это значит, что размер рабочих областей памяти используемых SQL операциями, затрачивающими большое количество ресурсов, такими как сортировка, группировка, HASH объединение или создание битовой карты будет управляться автоматически. По умолчанию значение параметра PGA_AGGREGATE_TARGET установлено в значение равное 20% от SGA.
STAR_TRANSFORMATION_ENABLED Определяет возможность использования трансформации типа "звезда" в процессе обработки запросов.
Оптимизатор запросов использует механизм кеширования результатов в зависимости от значения параметра RESULT_CACHE_MODE. Возможные значения параметра: MANUAL и FORCE
- Когда установлено значение MANUAL, вы должны в ручную указать HINT для оптимизатора, чтобы результат выполнения был помещен в кэш результатов.
- Когда параметр установлен в значение FORCE все результаты сохраняются в кэше результатов. Выражения в тексте которых указан HINT [NO_]RESULT_CACHE имеют более высокий приоритет перед значением системного параметра.
Размер памяти, выделенной для кэша результатов зависит от объема памяти SGA, а также системы управления памятью. вы можете изменить размер, выделяемый для кэша результатов установив соответствующее значение параметра RESULT_CACHE_MAX_SIZE.
Параметр RESULT_CACHE_MAX_RESULT определяет максимальное количество памяти в кэше результатов, которое может занимать один результат. Значение по умолчанию - 5%, можно указать любое значение от 1 до 100%.
Используя параметр RESULT_CACHE_REMOTE_EXPIRATION можно установить время (в минутах), которое будет действителен результат использующий удаленные объекты. Значение по умолчанию - 0, кеширование результатов обработки удаленных объектов запрещено. Установка этого параметра в не нулевое значение может заставить СУБД хранить в кэше результатов устаревшие результаты, например, если удаленная таблица используемая в результате изменяется в удаленной базе данных.
OPTIMIZER_INDEX_CACHING Этот параметр управляет расчетом стоимости кеширования индекса в сочетании с вложенным циклом или inlist итератором. Диапазон значений от 0 до 100 OPTIMIZER_INDEX_CACHING определяет процент блоков индексов в буферном кэше, который указывает оптимизатору на возможность кэширования индекса для вложенных циклов и inlist итераторов. Значение 100 предполагает, что 100% из блоков индексов, вероятно, будут найдены в кэше буферов и оптимизатор регулирует стоимость сканирования индекса или применения вложенного цикла соответственно. По умолчанию значение для этого параметра равно 0, что приводит к поведению оптимизатора по умолчанию. Будьте осторожны при использовании этого параметра, поскольку планы выполнения могут измениться в пользу кэширования индекса.
OPTIMIZER_INDEX_COST_ADJ позволяет управлять поведением оптимизатора в части выбора путей доступа с использованием индексов, то есть, чтобы сделать оптимизатор более или менее склонным к выбору пути доступа через индекс вместо полного сканирования таблицы. Диапазон значений составляет от 1 до 10000. Значение по умолчанию для этого параметра составляет 100 процентов, при этом оптимизатор оценивает пути доступа через индекс по обычной стоимости. Любое другое значение заставляет оптимизатор оценивать путь доступа на указанный процент от обычной стоимости. Например, значение 50 делает доступ по индексу в два раза дороже, его нормальной стоимости.
OPTIMIZER_MODE устанавливает режим работы по умолчанию для выбора подхода к оптимизации для любого экземпляра или сессии. Возможные значения:
OPTIMIZER_USE_SQL_PLAN_BASELINES включает и выключает возможность использования опорных линий SQL, хранящихся в SQL Management Base. Когда возможность включена, оптимизатор ищет выполняемое выражение в SQL Management Base, если выражение найдено, оптимизатор оценивает каждый план исполнения и выбирает план с самой низкой стоимостью.
OPTIMIZER_DYNAMIC_SAMPLING контролирует размер динамического семпла, захватываемого оптимизатором.
OPTIMIZER_USE_INVISIBLE_INDEXES включает или выключает использование оптимизатором невидимых индексов.
OPTIMIZER_USE_PENDING_STATISTICS определяет использование оптимизатором pending статистики при построении планов выполнения.

- ALL_ROWS: Оптимизатор использует стоимостной подход для всех SQL выражений сессии независимо от наличия статистики и оптимизирует их для достижения максимально возможной пропускной способности (минимальное использование ресурсов для обработки выражения). Значение по умолчанию.
- FIRST_ROWS_n: Оптимизатор использует стоимостной подход для всех SQL выражений сессии независимо от наличия статистики и оптимизирует их для достижения максимально быстрого времени ответа возвращая n количество строк. N может принимать значения 1,10,100,1000.
- FIRST_ROWS: Оптимизатор использует смешанный стоимостной и эвристический анализ для нахождения оптимального плана выполнения, задачей которого является вывод первых строк клиенту. Использование эвристики иногда приводит к генерации оптимизатором плана с значительно более высокой стоимостью, чем без использования эвристики. FIRST_ROWS работает только для обратной совместимости, рекомендуется использовать FIRST_ROWS_n.
OPTIMIZER_USE_SQL_PLAN_BASELINES включает и выключает возможность использования опорных линий SQL, хранящихся в SQL Management Base. Когда возможность включена, оптимизатор ищет выполняемое выражение в SQL Management Base, если выражение найдено, оптимизатор оценивает каждый план исполнения и выбирает план с самой низкой стоимостью.
OPTIMIZER_DYNAMIC_SAMPLING контролирует размер динамического семпла, захватываемого оптимизатором.
OPTIMIZER_USE_INVISIBLE_INDEXES включает или выключает использование оптимизатором невидимых индексов.
OPTIMIZER_USE_PENDING_STATISTICS определяет использование оптимизатором pending статистики при построении планов выполнения.
Возможности оптимизатора в разных релизах СУБД Oracle

Комментариев нет:
Отправить комментарий