Oracle Database 11g Настройка производительности.
5. Использование метрик и уведомлений

Мониторинг производительности требует наличие определенной информации, которая выходит за рамки статистики. ЧТобы определить, является ли данная статистика важной, вы должны знать сколько изменений произошло в системе с момента последнего её сбора. Для проактивного мониторинга необходимо получать уведомления о наступлении определенного события или достижении определенного события, например когда время отклика системы подойдет к разрешенному максимуму. Для диагностики проблем производительности, вы должны знать что изменилось. Метрики и уведомления предоставляют часть этой информации.
В общем случае, метрика привязывается к определенному показателю статистики производительности. Например количество физических чтений в секунду. Но существуют также метрики основанные на других событиях таких как "tablespace full" или "snapshot too old".
Пороговые значения могут быть выставлены для большинства метрик, и когда значение метрики превысит установленное пороговое значение, сгенерируется уведомление.
Ограничения базовой статистики

Статистика подсчитывает изменения которые происходят в БД. Статистика и события ожидания хранятся в сыром виде. Базовая статистика всегда имеет определенное значение в заданную единицу времени.
Если собирать базовую статистику на протяжении длительного периода времени, можно увидеть что значения со временем увеличиваются. На рисунке выше представлен возможный пример того как график для статистики физических чтений извлекается из представления производительности V$SYSSTAT. Как можно увидеть на рисунке, не смотря на то что статистическое значение одинаковое на обоих графиках, в конце периода наблюдения тенденция совершенно иная.
Для того чтобы лучше понимать поведение вашей БД, необходимо иметь возможность видеть кривую тенденции, а не просто какое то значение. Таким образом необходимо подсчитывать размер статистики в течение периода времени для определения тенденции роста или падения производительности в этот период.
Дополнительные средства
Базовая статистика представляет собой просто числа, просуммированные с момента старта экземпляра. Из базовой статистики можно получить значения, пригодные для анализа производительности только собирая их в течение какого то промежутка времени и затем сравнивая полученные промежуточные значения. Разница является дельтой для этих значений. Сервер Oracle включает в себя несколько средств для вычисления дельты. Statspack, AWR и настраиваемы скрипты могут производить отчеты содержащие дельту изменений между двумя снимками производительности.
AWR и Statspack позволяют сохранять наборы снимков для последующего анализа.
Метрики

Сервер БД Oracle собирает базовую статистику в процессе нормальных операций. Большинство метрик отслеживает темп изменений активности в сервере Oracle. Например, общее количество чтений в системе за последние 60 минут - это метрика. Метрики используются внутренними компонентами для мониторинга жизнеспособности системы, обнаружения проблем, и самостоятельной настройки. Процесс Manageability Monitor (MMON) периодически обновляет данные метрик из соответствующей базовой статистики.
Компоненты сервера БД используют метрики для представления функций управляемости. Например, ADDM использует показатель общего количества физических чтений в системе за последние 60 минут в качестве входных данных. Другому компоненту может потребоваться другая метрика основанная на той же базовой статистике по физическим чтениям. Например, memory advisor может использовать статистику по физическим чтениям в часы пиковой нагрузки. СУБД Oracle 11g поддерживает создание метрик по системным событиям, сессиям, файлам и событиям ожидания. Каждая метрика уникально обозначается номером и именем метрики. На рисунке представлены некоторые представления из которых вы можете получить данные по метрикам.
Преимущества использования метрик
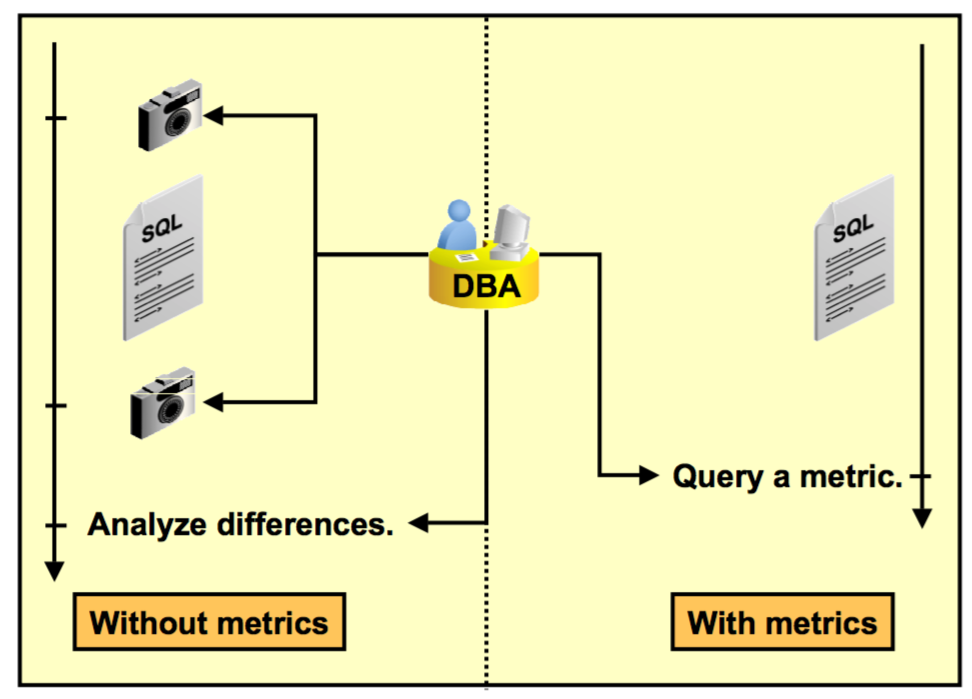
Главным преимуществом использования метрик это возможность сбора данных в процессе работы приложения. Серверные компоненты с появлением метрик имеют базис для самонастройки и проверки состояния компонентов. Метрики предоставляют информацию, требуемую AMM и ADDM.
Представления, содержащие историю метрик

Значения метрик представлены в некоторых представлениях V$, где значения средние за сравнительно маленький интервал. Интервал может варьироваться в зависимости от класса метрики и составляет от 15 до 10 секунд. Снимки данных из представлений v$ сохраняется в таблицы DBA_HIST.
На рисунке представлены некоторые из представлений V$:
Например:
V$SYSMETRIC_HISTORY отражает все системные метрики доступные в БД. В этом представлении отображаются как метрики с высокой продолжительностью (интервал 60 секунд с хранением истории до часа) так и метрики с низкой продолжительностью (интервал 15 секунд без хранения истории).
V$SYSMETRIC_HISTORY отражает все системные метрики доступные в БД. В этом представлении отображаются как метрики с высокой продолжительностью (интервал 60 секунд с хранением истории до часа) так и метрики с низкой продолжительностью (интервал 15 секунд без хранения истории).
DBA_HIST_SESSMETRIC_HISTORY отражает историю изменения некоторых метрик критичных для сессии. В данном рпедставлении содержится снимки из представления V$SYSMETRIC_VIEW.
Использование Enterprise manager для просмотра метрик

Используя страницу Метрик можно просмотреть список всех метрик производительности, доступных в БД.
Гистограммы статистики

Хотя метрики могут дать представления тенденции изменения статистики, они не могут указать на узкие места в системе, или на локализацию ресурсов сессиями. Например вы можете наблюдать высокие показания метрик, но это внезапное увеличение может быть вызвано всего одной или двумя сессиями в вашей системе. В этом случае может быть и не имеет смысла исследовать данный всплеск активности. В тоже время если резкое увеличение показателей метрики относится ко всей системе, проблему нужно устранять. Данная информация доступна в представлениях гистограм производительности. Как показано на рисунке, вы наблюдаете резкое увеличение ввода/вывода на вашу систему. Вы можете связать эту информацию с соответствующей I/O гистограммой, найденой в V$FILE_HISTOGRAM. Данное представление показывает гистограмы поблочного чтения основываясь на файлах. Эти гистограмы состоят из частей разделенных между собой интервалом времени, измеряемом в милисекундах. значение в каждой части - это количество событий ожидания системы в заданную единицу времени. На примере показанном на рисунке видно, что система ждала 5500 раз в течение более чем 32 мс и менее 64 мс для чтения блоков с дисков. Это безусловно является причиной для беспокойства если время доступа к данным в вашей системе не должно превышать 10 мс, и проблему нужно решать. Если бы вы видели большое количество в более короткие периоды времени ожидания, повода для беспокойства бы не было.
Метрики позволяют выявить потенциальные проблемы производительности.
Просмотр гистограмм

V$EVENT_HISTOGRAM показывает гистограммы количества ожиданий основываясь на событиях.
V$FILE_HISTOGRAM показывает гистограммы поблочного чтения основываясь на файлах.
Также гистограммы можно просмотреть в Enterprise manager, перейдя на вкладку производительность.
Гистограммы не будут заполняться, если не выставлен в TRUE параметр инициализации TIMED_STATISTICS. Данный параметр выставляется по умолчанию при установке значения STATISCTICS_LEVEL в TYPICAL или ALL.
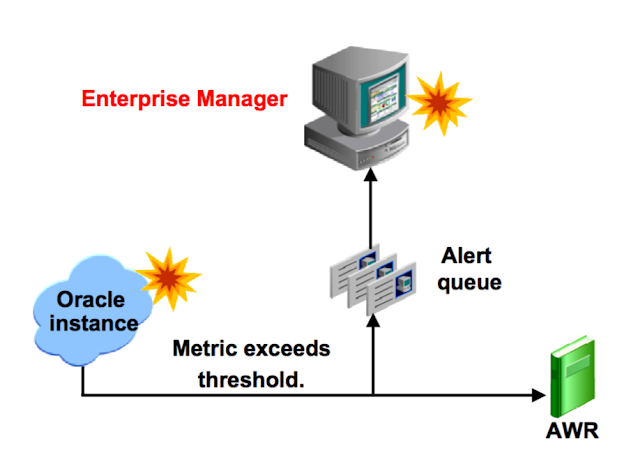



Предупреждения, генерируемые сервером

Предупреждения (Alert) это уведомления о событиях, приводящих к нежелательным последствиям для БД. По умолчанию, БД Oracle отправляет предупреждения через Enterprise Manager, где они в последствии отображаются.
Дополнительно, EM может быть сконфигурирован на отправку уведомлений по электронной почте. Сервер Oracle также хранит историю метрик и предупреждений в репозитории нагрузки.
Процесс постановки в очередь предупреждений - это постоянный многопользовательский процесс, он также доступен для пользователей, которые хотят записать кастомизированные обработчики предупреждений.
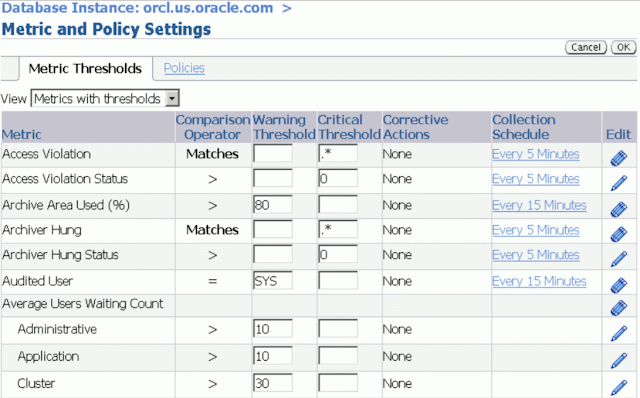
Пороговые значения на некоторых ключевых метриках, например Tablespace Used (%), установлены по умолчанию. Вы можете вручную выставить пороговое значение на соответствующие метрики вашей системы. Если база данных отклоняется от нормальных показаний достаточно , чтобы пересечь эти пороговые значения, Oracle Database 11g проактивно уведомит вас выслав предупреждение. Ранне оповещение о потенциальных проблемах позволяет вам быстро реагировать, и довольно часто устранять проблемы до того как пользователи узнают о них.
Ключевые метрики которые могут заранее уведомить о проблемах:
- Average File Read Time (в сантисекундах)
- Response Time (на транзакцию)
- SQL Response Time (%)
- Wait Time (%)
Модель использования предупреждений
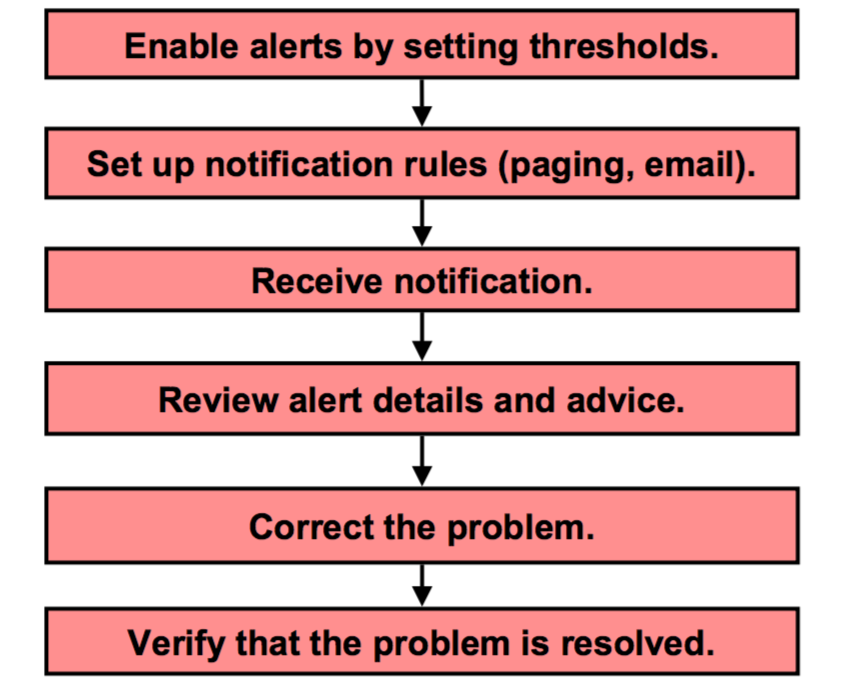
Ниже представлено описание модели, наиболее часто используемой для предупреждений генерируемых сервером:
- Если необходимо, вы можете изменить пороговое значение для предупреждения генерируемого сервером.
- Вы можете сделать это используя EM или PL/SQL пакет
- Вы устанавливаете правила уведомления используя EM
- Когда предупреждение сгенерировано, EM отображает его на странице предупреждений
Перед использованием уведомлений и предупреждений, вы должны убедиться что STATISTICS_LEVEL имеет значение TYPICAL или ALL.
Установка пороговых значений

Создание и тестирование предупреждений

Пример: Вы решили, что в должны получать критическое предупреждение если в табличном пространстве INVENTORY место будет занято более чем на 75%. (функция авто расширения не доступна для файлов данных этого табличного пространства)
Представления для просмотра метрик и предупреждений

Когда активны, значения метрик регулярно подсчитываются MMON и хранятся в памяти в течение часа. Значения метрик, хранящихся в памяти можно посмотреть в представлении V$SYSMETRIC и V$SYSMETRIC_HISTORY. Такие же представления доступны для метрик уровня сервиса.
Метрики, записываемые на диск активируются просто включением механизма автоматического создания снимков AWR. Просмотреть этот класс метрик можно обратившись к представлениям вида DBA_HIST_*. Политика очистки для истории метрик акая же как для снимков AWR.
Следующие представления словаря данных позволяют получить информацию о системных предупреждениях:
- DBA_OUTSTANDING_ALERTS содержит предупреждения которые были выделены сервером Oracle как активные.
- DBA_ALERT_HISTORY представляет исторические записи предупреждений, которые больше не являются активными.
- V$ALERT_TYPES дают информацию о каждом типе предупреждений, генерируемых сервером.
Комментариев нет:
Отправить комментарий